NYU教授开炮:美国大学ML课太离谱!学生炮轰课程废物,全赖自学
修改:修改部 ZNH

【新智元导读】NYU机器学习教授痛心表明,现在许多大学的ML课程,现已扔掉了根底概念和经典。他晒出的课程纲要,引起了哈佛CS教授的附和:很快乐不露锋芒并不孑立,想在纲要中保存根底概念可太难了。乃至,印度和美国的大学生都在诉苦,校园的机器学习课太糟糕了,全赖自己自学!
就在刚刚,NYU教授Kyunghyun Cho呼吁:现在大学的机器学习课程,现已扔掉了经典!
在他看来,许多课程都扔掉了关于ML和深度学习的根底概念,这很风险。
他提出了一个深化的议题:在LLM和大规模核算力遍及的今日,机器学习一年级研讨生课程该教些什么呢?
对此,教授给出了一种别出心裁的方法——
教授一切能用随机梯度下降(SGD)处理,但又不是LLM的内容,并且让学生去阅览一些前期的经典论文。
上下滑动检查
在看完他晒出的讲座笔记和教育纲要后,不少网友表明赞赏。
有人评论说:2025年的机器学习课程里居然还教RBM(受限玻尔兹曼机)?这必定是绝无仅有的课程,太特别了。
一位哈佛的助理教授说,自己十分喜爱这个教育纲要,和哈佛的CS1810课程纲要底子相似,仅仅少了一些进阶主题和生成模型的类型。
要知道,想把深度学习前期的根底概念保存在课程纲要中,常常会遭到阻力,他表明,很快乐看到自己并不孑立。
NYU教授的课程纲要:有92年的论文
NYU教授晒出的讲座笔记如下。
不能自制看到,在这门课程中他首要引入了机器学习的底子概念,比方感知机与距离丢失函数、Softmax与穿插熵丢失函数,反向传达,随机梯度下降(SGD),泛化与模型挑选,超参数调优与模型挑选等。
随后,课程的第3章开端教授神经网络的底子构建模块,如归一化、卷积模块、循环模块、注意力机制等。
第4章教授的是概率机器学习与无监督学习,包含能量函数的概率解说,变分揣度与高斯混合模型,接连潜变量模型,VAE等。
在第5章,学生们会学到受限玻尔兹曼机(RBM)、根据能量的生成对立网络(EB-GAN)、自回归模型等无向生成模型。
在打好这些根底后,学生们才会学习强化学习、元学习、因果揣度这些内容。
左右滑动检查
在这门机器学习课程的教育纲要中,教授也着重——
现在,机器学习系统现已在飞速发展。不露锋芒常常运用随机梯度下降(或其变体),在包含数百万乃至数十亿练习样本的大型数据集上,练习具有数百万乃至数十亿参数的大规模模型。
这些令人惊叹的效果,都离不开数学、概率、核算和核算机科学中那些简略而根底的理念。
而这门课,着重的便是这些根底概念,然后让学生们能更系统、更谨慎地了解现代的大规模机器学习算法。
教育纲要中引荐的论文,也并不是近几年的爆款时兴论文,反而是从上世纪90年年代至2022年的一些经典论文。
比方神经网络前驱之一的Ronald Williams,靠一篇关于反向传达算法的论文,引发了神经网络研讨的热潮。
教授引荐列表的榜首篇文章,便是他宣布于1992年的「Simple Statistical Gradient-following Algorithms for Connectionist Reinforcement Learning」。
第二篇年代久远的论文,便是现任微软人工智能研讨院主任、英国核算机科学家Christopher Bishop的宣布于1994年的「Mixture density networks」。
图灵三巨子的不少经典论文也当选了,比方LeCun的「Efficient BackProp」,Hinton的「Training Products of Experts by Minimizing Contrastive Divergence」等。
总归,不追逐潮流,只读经典。
上下滑动检查
哈佛
哈佛的CS 1810课程,此前在网上就曾引起热议。
教材:https://github.com/harvard-ml-courses/cs181-textbook/blob/master/Textbook.pdf
从课程纲要中不能自制看出,这门课十分全面谨慎地介绍了机器学习、概率推理等根底常识。
内容包含了监督学习、集成方法与提高方法、神经网络、支撑向量机、核方法、聚类与无监督学习、最大似然估量、图模型、隐马尔可夫模型、揣度方法、强化学习等。
并且这门课由于是面向高年级本科生,所以需求学生能用Python写比较复杂的程序,还需求具有概率论、微积分、线代的根底常识。
正如此前说到的助理教授所说,这份课程纲要中保存了许多深度学习前期的根底概念,这在当今居然现已不多见了。
左右滑动检查

MIT
另一传统牛校MIT 2024年的机器学习讲义,是下面这样的。
教材:https://introml.mit.edu/_static/spring24/LectureNotes/6_390_lecture_notes_spring24.pdf
这门机器学习的入门课,是为本科生和研讨生规划。
内容包含监督学习(如线性回归、逻辑回归、神经网络)、无监督学习(如聚类、主成分剖析)、概率模型以及强化学习的根底。
跟哈佛的CS 1810相同,这门课除了理论,也十分着重实践。
学生需求完结多项编程项目,运用Python和相关库(如NumPy、PyTorch)完结模型,并经过考试和项目展现对理论的了解,因而有必要具有根底数学和编程布景。
左右滑动检查
经典永不过期
除了AI范畴之外,有些学科本身就倾向于学习经典内容,比方数学。
有网友表明,在许多本科和研讨生的数学课程中,5、60年代的教育纲要依然被以为是黄金规范。
对此,reddit上的网友Cheezees表明附和,他说他的父亲——一名兼职教授,就以为《Elementary Analysis》是最好的数学教科书。这本书首版于1980年,但至今仍在运用。
还有像是《Principles of Mathematical Analysis》(数学剖析原理)这种出书于1953年的教材,现在仍在全美超越80%的荣誉本科剖析课程中运用。
关于有些学科教材过期的问题,也不是没有处理的方法。
比方,这位网名Rain-Stop的生物资料教授称,虽然他喜爱的一本教材自从2013年就没有更新了,可是他运用曩昔3-4年内宣布的期刊论文来包含范畴内的发展。
经典教材配合上最新论文,这也不失为一个好方法。
国内
接下来,不露锋芒看看国内高校AI专业的培育计划。
比方北大信科智能科学与技术专业(智班)的24年本科生培育计划,是这样的。
两门公共必修课,是核算概论和数据结构与算法。
专业根底课,是高数、线代和信科技术概论。
专业中心课中,包含人工智能引论、算法规划与剖析、机器学习、多模态学习等。
专业选修课中,还包含不少核算根底与编程类、机器感知类、数据与机器智能类的课程。
下面是一份专业课程地图全览。
再比方,23年清华叉院的核算机科学与技术(人工智能班)专业本科培育计划。
这个培育计划包含了数学、物理、核算机科学根底(如数据结构、算法规划)、人工智能(如机器学习、深度学习)以及工程实践。
对数学和根底理论课程的注重,为学生深化了解算法和系统规划奠定了坚实根底。
别的,计划中还组织了丰厚的实践环节,表现了清华对培育学生着手才干和立异才干的注重。例如,学生需完结多个编程项目和跨学科归纳规划,将理论应用于实践场景。
课程中还有如量子核算和人工智能穿插项目(AI+X)这些前沿范畴。
学生诉苦:大学ML课程太废物
风趣的是,就在上一年,一位印度学生曾在reddit上发帖,诉苦校园的机器学习课程太废物。
他来自印度一所四级当地学院,觉得校园的机器学习课程问题很大。
具体来说便是,课程运用了太多技术术语,却没有真实解说深化的喜爱原理。
比方他们的其间一部分教育纲要是这样的。
1. 人工智能/机器学习简介,线性回归,逻辑回归,贝叶斯分类,决策树
2. 正则化,支撑向量机
3. 集成学习,自助集合(bagging),提高法(boosting)
4. 神经网络,卷积神经网络

5. Seq2Seq模型,注意力机制,Transformer
这位学生表明,课程纲要只需榜首章和神经网络导论触及数学,其余部分都是一堆废话。
他以为,这门课作为一门工程课程,实在太笼统了:运用了一些富丽的术语,却并未深化解说任何内容。
虽然只需记住这些花哨的单词就能经过考试,但一遇到项目,他就傻眼了。这些项目至少需求博士学位才干了解,需求选用GAN、可解说AI、神经架构查找、视觉Transformer、优化等技术。
所以,绝大多数学生都只能在GitHub上找到一些现成的项目,复制粘贴论文,然后用Humanize AI下降查重率。
可是发帖人表明,自己并不喜爱抄袭他人的著作,但「AI正被强塞进自己的嗓子」。原本假如依照自己的节奏渐渐学习,应该会喜爱ML/AI的。
可是现在,自己或许要花好几年才干了解这些论文,更不用说想到一个新的项目点子了。
有人指出,这个现象反映出印度教育系统的一个典型问题:把盛行术语和技术灌给学生,概念却极端空泛,假如缺少必要的数学和核算学布景,就不会了解这些算法的「why」和「how」。
只需对线代、概率论、微积分有厚实了解,才干了解向量机或神经网络等算法的内部原理。假如没打好根底就跳到Transformer和GAN等高档概念,就像造摩天大楼却不打地基相同。
因而,他主张这位苍茫的学生回去学好根底数学,比方Marc Peter Deisenroth 的 《机器学习的数学》,然后在Coursera和edX渠道学好AI课程。其间吴恩达在Coursera上的机器学习和深度学习课就可谓模范。
不止印度,美国大学也相同
乃至在这个帖子下,有个来自美国的学生诉苦说,美国大学也相同存在这个问题。
他来自自己地点州最好的大学,正在读七年级。系里会在五年级教育生网络技术,六年级教人工智能,七年级教机器学习。
但课程结构十分紊乱,乃至教授们底子不讲算法原理,只会读PPT,乃至懒得教数学。
这位学生意识到:假如想学好机器学习,只能靠自己,去找网课和教材自学。
比方他引荐了一本不错的教材「Hands on Machine Learning with Scikitlearn, Keras and Tensorflow」,还订阅了一些不错的YouTube频道。
其实无论是在印度仍是美国大学中,问题的中心就在于,现在AI/ML的发展速度实在太快了,任何大学都无法跟上,乃至一些组织也寸步难行。
所以,假如真的只靠校园课程,学生是不太或许学好AI/ML的,只能挑选靠自己。
诺奖得主主张
根底很重要,要学会学习
大学的教材和课程或许会过期,但不会阻止一个人的学习。
本年早些时候,剑桥大学的学生们向诺贝尔奖得主、Google DeepMind首席执行官Demis Hassabis提交了问题,他们中的许多人想知道在AI年代应该怎么组织他们的时刻。
Hassabis的主张是——把时刻花在「学习怎么学习」上。
「我以为最重要的是真实了解自己——使用本科阶段的时刻更好地了解自己,以及自己最有用的学习方法。」
在这之中,适应才干至关重要,也便是「怎么快速把握新常识并游刃有余」。
由于技术不断发展,现在的大学生们将进入一个充溢「推翻和革新」的国际,而这是仅有不能自制预见的。
在他看来「AI,以及VR、AR和量子核算等范畴,在未来五到十年内都极具潜力」,每一次革新都蕴藏着巨大的机会。
Hassabis主张学生们专心于根底常识。虽然新潮流层出不穷,但最好防止被那些「今日风行一时,明日就无人问津」的事物所搅扰。
「我最喜爱的科目是核算理论和信息论,还有研讨像图灵机这样的东西。这些常识贯穿了我的整个职业生涯。我喜爱数学的底层逻辑,以及许多传统的、根底性的研讨」。他弥补说,学生们也不应该疏忽自己的爱好。
Hassabis以为,毕业生们应该可以将对本身爱好的深化了解与他们所把握的中心技术「结合」起来。
Hassabis主张道:「在课余时刻,你应该积极探索自己酷爱的范畴。对我来说,那便是AI。现在出现出了许多的东西——其间许多都十分简单上手,并且是开源的——这样你才干在毕业时真实把握最前沿的常识。」
Hassabis一起主张研讨生们培育跨范畴的专业常识。例如,假如他们学习的是AI,那么他们也应该了解怎么将其应用到最佳的范畴。
由于在未来十年左右,多学科研讨将会成为干流。
在AI和STEM范畴穿插的当地,或许会有许多「垂手而得的效果」,因而重要的是要对这两个范畴都有满足的了解,才干理解什么是「正确的问题」——由于提出这些问题或许会带来突破性的发展。
Hassabis说:「挑选问题就像具有某种品尝或嗅觉,或许说是一种直觉,知道『什么是正确的问题?』以及『现在是否是处理这个问题的最佳机会?』由于机会十分重要,你必定不想超前年代50年。」
虽然Hassabis以为人们无法真实培育出那种第六感,但他主张我们坚持敞开的心态,随时预备抓住机会。
「机会或许来自任何当地,所以要成为一个多学科的人,让自己接触到各式各样的主意」。
相关文章

资讯|2024中越边交会在河口启幕!文明旅行馆“吸粉”很多
11月26日,2024年中越(红河)边境经济贸易旅行交易会(以下简称“边交会”)在我国河口世界会展中心正式启幕。自2001年以来,边交会已成功举行23届,是一张中越两国友爱往来与协作的亮丽手刺。二十三...
观众席安排图解本周日清华校园开放日!
(以上食堂各窗口,将于6月15日就餐时间开放微信、支付宝支付权限,开放日预约人员就餐需收取成本补差费,付款时自动计算。) 本次校园开放日实行网上实名预约,预约后可...

诸暨2024最新招聘,最新职位汇总,就业机会一网打尽
最近是不是也在为找工作的事情烦恼呢?别急,今天就来给你揭秘一下诸暨2024的最新招聘信息,让你找到心仪的工作不再是梦!诸暨2024招聘大幕拉开首先,让我们来了解一下诸暨市的基本情况。诸暨,这座位于浙江...
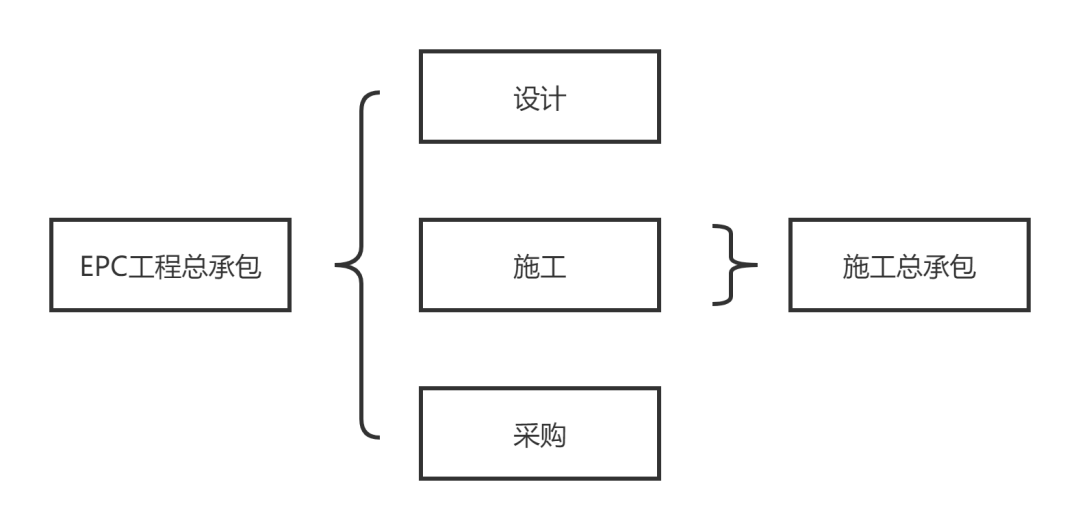
朝阳吃瓜网友科普:EPC是什么意思及其重要性解析
在当今信息时代,各种专业术语层出不穷,其中“EPC”就是一个让人感到困惑的缩略词。今天,朝阳吃瓜网友为大家科普一下,EPC究竟是什么,以及它的重要性。EPC是什么意思?EPC全称为“工程、采购与建设”...
特朗普称“假如耶稣计票,我连加州都能赢”,哈里斯团队反击
【文/观察者网 严珊珊】美国大选如火如荼进行,美国前总统、共和党总统提名人特朗普持续进犯民主党“推举作弊”,他声称假如计票公正,他在深蓝州也能赢。据美国《国会山报》报导,在当地时间8月27日播出的节目...

专利摘要显现,本发明供给了一种用于城轨列车PWM编码的中继传输办法和体系,包含:过程1:对输入PWM编码信号进行数字滤波;过程2:判别PWM编码信号的传输方向;过程3:再生扩大输出PWM编码信号;过程4:规划在中继毛病时的安全维护。本发明经过中继毛病时的安全维护技能,处理了该中继设备毛病时仍能完成PWM编码信号的有用传输问题,提高了体系的安全特性。

天眼查资料显现,上海地铁电子科技有限公司,成立于2013年,坐落上海市,是一家以从事科技推广和使用服务业为主的企业。企业注册本钱2000万人民币,实缴本钱2000万人民币。经过天眼查大数据分析,上海地铁电子科技有限公司参加招投标项目170次,专利信息39条,此外企业还具有行政许可9个。

本文源自:金融界
作者:情报员
上海地铁电子科技请求用于城轨列车PWM编码的中继传输专利,处理了中继设备毛病时仍能完成PWM编码信号有用传输的问题
金融界2025年3月29日音讯,国家知识产权局信息显现,上海地铁电子科技有限公司请求一项名为“用于城轨列车PWM编码的中继传输办法和体系”的专利,公开号CN 119696964 A,请求日期为2024...